前言 前阵子不知道为啥,一直用的域名突然被阿里云封了,申诉也不给解封,只好换个域名。正好整理一下博客,太久没更新都吃灰了,新的博客地址是 https://blog.catcat.work
需求 B 站 6 级之后可以通过在手机端 答题升级为 “硬核会员”。题库分为几个分区,用户可以选择其中的一个或几个分区去答题,总共 100 道题,2 小时内答对 60 道就算通过。题目都是选择题。对我来说,直接答题太困难了,百度搜 100 道题又太费时间,不如直接写个脚本,自动 “搜索” 参考答案。
思路 期望的效果是:界面出现题目后,脚本可以自动获取参考答案。细化一些考虑,问题首先可以被拆分成两步:
第一步:获取界面中展示的题目和选项的文字 内容
第二步:根据题目和选项获取参考答案
第一步可以使用无障碍、OCR等工具实现获取屏幕中的文字内容,简单起见使用OCR就够了。
第二步的话,很久以前写过一个微信读书自动答题的脚本,是用的百度搜索,但效果太差了。大模型做这种问答类的题目其实效果还是蛮不错的,毕竟经过大量的数据训练,学习过大量的知识。ChatGPT 还是有些贵的,为了降低成本,直接用便宜的国产大模型
我们的最终目标是答对 60 题,对于题目类别的话,尽可能选取一些答案比较确定或者参考资料比较多的。如果是鬼畜区什么的,出现了什么新的梗 GPT 可能不知道,正确率也就保证不了了。(下图是网上搜的)
相对来说,文史类的答案可能会更容易搜到一些(至少参考资料会多一些),就它了!
实现 先说下开发环境,脚本是在 Python 3.12 环境下开发的。进入正题~
获取窗口截图 识别题目的第一步是获取截图。我们可以连接真机,在手机上打开 adb 调试,然后使用 adb shell screencap 命令获取截图。也可以直接在电脑装个模拟器(这里装的是 Mumu 模拟器),直接给模拟器窗口截图。后者简单很多,我们直接用后者实现。
为了截取屏幕上某个窗口的画面,我们首先需要知道窗口的位置和大小,这可以使用 pygetwindow 库,导入这个库后就可以直接根据黄口标题搜索窗口:
1 2 3 4 5 6 7 8 9 10 import pygetwindow as gwwindow_list = gw.getWindowWithTitle("MuMu模拟器" ) window = window_list[0 ] print (window.x, window.y, window.width, window.height)
上面几行代码就可以直接输出模拟器窗口的位置和大小。知道了窗口的位置和大小之后,我们就可以使用 Pillow 截图啦:
1 2 3 from PIL import ImageGrabscreenshot = ImageGrab.grab(bbox=(window.x, window.y, window.width, window.height))
到这里,截图的代码就写完了。也可以调整截取区域的 y 坐标和高度,截取的区域小一些,后面调用 OCR 识别文字也会快一些,效果:
识别题目 图截完了,下一步是获取题目和内容。这里使用 Paddlepaddle 提供的 OCR 模型进行识别。PaddleOCR v4 提供了文本检测、文本识别、文本方向识别三类模型。其中文本检测是用来识别图片里哪里存在文字, 文本识别是来识别图片中文字的具体内容是什么,文本方向识别用来识别图片中文字的方向。为了识别截图中文字的内容和位置,我们三个模型都要用到。
每类模型还分成轻量型、高精度型等等,官网上也分别提供了几个模型文件的下载。以中文文本检测模型为例,轻量版推理模型的大小为 4.7M,而高精度版推理模型的大小是 110M。在使用体验上,高精度版的效果可能会更好,但速度会更慢。我直接在 CPU 上跑的,实测轻量版效果完全够用,并且速度还能接受(识别一张图片的文字大概不到 3 秒)。
接下来进行代码实现:
1 2 3 4 5 6 7 8 from paddleocr import PaddleOCRimport numpy as npocr = PaddleOCR(use_angle_cls=True , lang="ch" , det_model_dir='文本检测模型的目录' , rec_model_dir='文本识别模型的目录' , cls_model_dir='文本方向识别模型的目录' ) img_array = np.array(screenshot) result = ocr.ocr(img_array, cls=True )
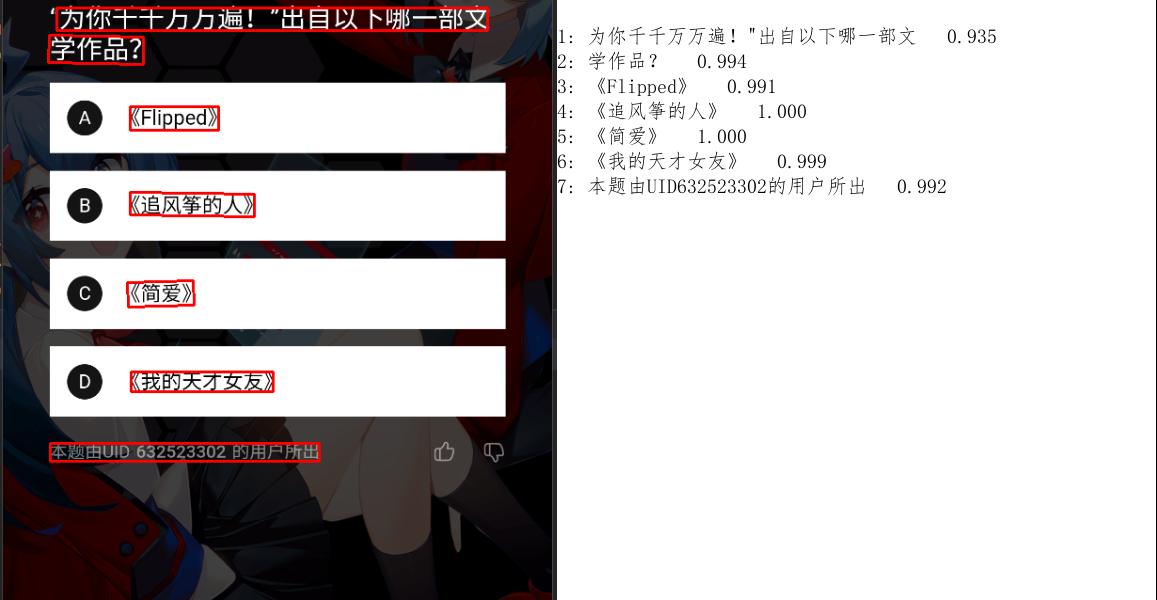
这样图片中的文字就识别好了。我们也可以使用 paddleocr 提供的 draw_ocr 把识别到的文字画出来:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from paddleocr import draw_ocrfor idx in range (len (result)): res = result[idx] for line in res: boxes = line[0 ] text = line[1 ][0 ] result = result[0 ] image = img.convert('RGB' ) boxes = [line[0 ] for line in result] txts = [line[1 ][0 ] for line in result] scores = [line[1 ][1 ] for line in result] im_show = draw_ocr(image, boxes, txts, scores) im_show = Image.fromarray(im_show) im_show.save('result.jpg' )
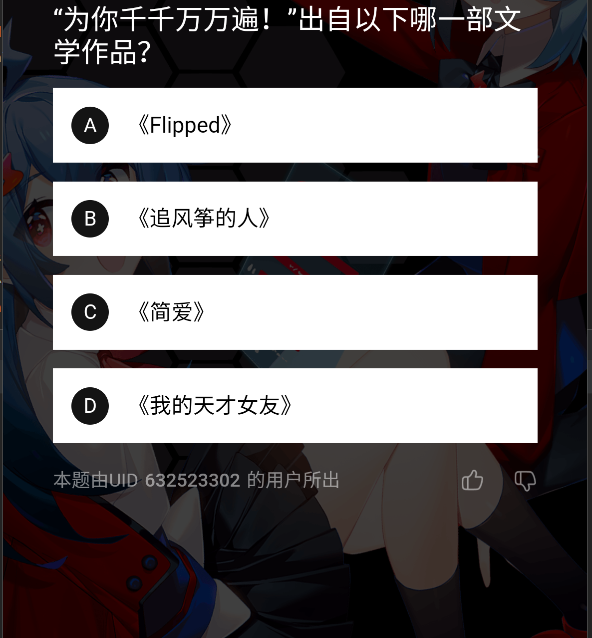
至于如何分辨文字是题目还是选项,直接根据位置特征来就好啦。题目部分文字的左边界始终在距离左侧屏幕大约 100 像素以内的位置;选项部分的位置特征也很明显,每行文字距离顶部一定超过 64 个像素,并且距离左侧边界的位置比较远。
以图中为例,我们通过上面这种策略就可以组合出问题和答案 –
问题是: 为你千千万万遍” 出自以下哪一部文学作品?
自动答题 自动答题这一步,我们使用大模型来做。首先给大模型定义一个角色,告诉它它是一个答题专家(定义 system role):
1 2 3 4 - 你是一个通晓古今的百科全书,拥有丰富的学识和答题经验。现在需要你根据用户输入的问题 <Question> 以及选项 <Option> 选出一个最合适的选项 <Answer>,然后输出选项的内容。 - 需要注意,你的答案仅能是从选项中选择,不能自由发挥。 - 题目类型都是选择题,一部分是问题选项,另一部分需要你从选项中选出一个最合适的填补题目的空缺。题目的空缺会用连续的下划线__表示。 - 你只需要回答你认为正确的选项,不需要做出任何解释。你的答案需要有理论依据,不可以回答虚构的答案。
接下来,可以给它一些样例输入,让它有些参考依据:
1 2 3 4 5 6 7 8 - 用户输入: <Question>最古老的文学体裁是什么? <Option>诗歌 <Option>小说 <Option>散文 - 输出: <Answer>诗歌
剩下要做的就是调接口啦:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 import requestsimport jsonkey = "sk-xxxxxxx" url = "https://api.xxxxxx.com/chat/completions" def llm (questionBody ): payload = json.dumps({ "messages" : [ { "content" : "- 你是一个通晓古今的百科全书,拥有丰富的学识和答题经验。现在需要你根据用户输入的问题 <Question> 以及选项 <Option> 选出一个最合适的选项 <Answer>,然后输出选项的内容。\n- 需要注意,你的答案仅能是从选项中选择,不能自由发挥。\n- 题目类型都是选择题,一部分是问题选项,另一部分需要你从选项中选出一个最合适的填补题目的空缺。题目的空缺会用连续的下划线__表示。\n- 你只需要回答你认为正确的选项,不需要做出任何解释。你的答案需要有理论依据,不可以回答虚构的答案。\n" , "role" : "system" }, { "content" : "<Question>最古老的文学体裁是什么?\n<Option>诗歌\n<Option>小说\n<Option>散文\n" , "role" : "user" }, { "content" : "<Answer>诗歌" , "role" : "assistant" }, { "content" : f'<Question>{questionBody} ' , "role" : "user" } ], "model" : "xxxxxx" , "frequency_penalty" : 0 , "max_tokens" : 2048 , "presence_penalty" : 0 , "response_format" : { "type" : "text" }, "stop" : None , "stream" : False , "stream_options" : None , "temperature" : 1 , "top_p" : 1 , "tools" : None , "tool_choice" : "none" , "logprobs" : False , "top_logprobs" : None }) headers = { 'Content-Type' : 'application/json' , 'Accept' : 'application/json' , 'Authorization' : f'Bearer {key} ' } response = requests.request("POST" , url, headers=headers, data=payload) return response.json()["choices" ][0 ]["message" ]["content" ]
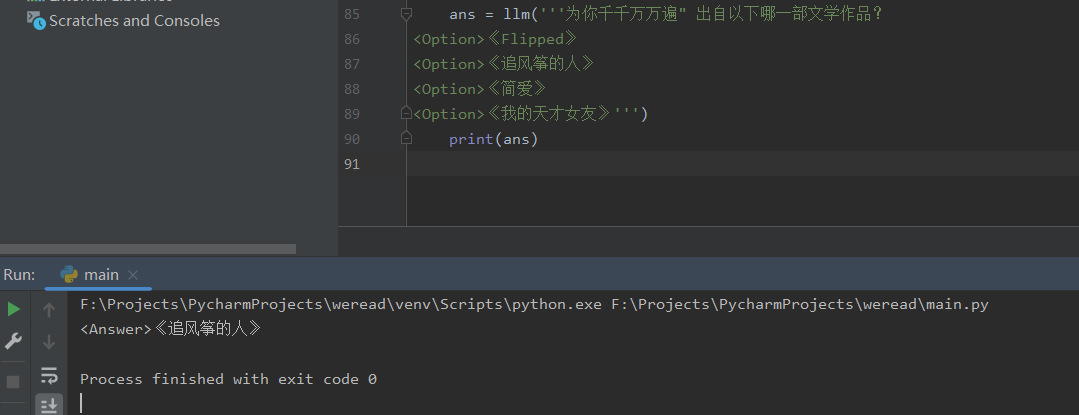
调一下接口尝试一下:
1 2 3 ans = llm('为你千千万万遍" 出自以下哪一部文学作品?\n<Option>《Flipped》\n<Option>《追风筝的人》\n<Option>《简爱》\n<Option>《我的天才女友》' ) print (ans)
好了,这道题选B~
效果 最后只需要把上面的过程串起来就好啦,把 OCR 识别出的题目和答案送给大模型,让大模型帮忙选个答案。有了这个助手,分分钟通关硬核会员~
而成本只有不到两分钱:
完结撒花